ICT이노베이션스퀘어 AI기본과정(CNU) 교육을 듣고 정리한 내용입니다.
AI기본과정(CNU) 교육 자료를 참고하였습니다.
라이브러리를 이용한 데이터 수집
정적 크롤링
1. 정적 웹 페이지 크롤링 준비
(1) BeautifulSoup 연습 1
BeautifulSoup 라이브러리 사용을 위한 추가 설치작업 : 명령 프롬프트 창에서 pip 명령 사용
pip install beautifulsoup4
BeautifulSoup import
from bs4 import BeautifulSoup
연습용 html 작성
html = '<h1 id="title">한빛출판네트워크</h1><div class="top"><ul class="menu"><li><a href=http://www.hanbit.co.kr/member/login.html class="login">로그인 </a></li></ul><ul class="brand"><li><a href="http://www.hanbit.co.kr/media/>한빛미디어<li><a href="http://www.hanbit.co.kr/academy/">한빛아카데미</a></li></ul></div>'
BeautifulSoup 객체 생성
soup = BeautifulSoup(html, "html.parser")
객체에 저장된 html 내용 확인
print(soup.prettify())
(2) BeautifulSoup 연습 2
지정된 한 개의 태그만 파싱
soup.h1
tag_h1 = soup.h1
tag_h1
tag_div = soup.div
tag_div
tag_ul = soup.ul
tag_ul
tag_li = soup.li
tag_li
tag_a = soup.a
tag_a
지정된 태그를 모두 파싱
tag_ul_all = soup.find_all("ul")
tag_ul_all
tag_li_all = soup.find_all("li")
tag_li_all
tag_a_all = soup.find_all("a")
tag_a_all
속성을 이용해 파싱
- attrs : 속성 이름과 속성값으로 딕셔너리 구성
- find() : 속성을 이용해 특정 태그 파싱
- select() : 지정한 태그를 모두 파싱하여 리스트 구성 / 태그#id 속성값, 태그.class 속성값
tag_a.attrs
tag_a["href"]
tag_a["class"]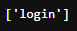
tag_ul_2 = soup.find("ul", attrs = {"class" : "brand"})
tag_ul_2
title = soup.find(id = "title")
title
title.string
li_list = soup.select("div>ul.brand>li")
li_list
for li in li_list:
print(li.string)
2. 정적 웹 페이지 크롤링 실습
(1) 크롤링 허용 여부 확인
- 웹 페이지를 크롤링하기 전에 크롤링 허용 여부를 확인하기 위해 주소 창에 "크롤링할 주소/robots.txt"를 입력
- 만약 robots.txt 파일이 없다면 수집에 대한 정책이 없으니 크롤링을 해도 된다는 의미
| 표시 | 허용 여부 |
| User-agent: * Allow: / 또는 User-agent: * Disallow: |
모든 접근 허용 |
| User-agent: * Disallow: / |
모든 접근 금지 |
| User-agent: * Disallow: /user/ |
특정 디렉토리만 접근 금지 |
(2) 웹 페이지 분석
매장 정보 찾기 : 할리스 (hollys.co.kr) 접속 -> Store -> 매장검색

HTML 코드 확인 : 마우스 오른쪽 버튼 -> 페이지 원본 보기

페이지별 웹 페이지 주소 확인
- 1페이지 : https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=1&sido=&gugun=&store=
- 2페이지 : https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=2&sido=&gugun=&store=
- 3페이지 : https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=3&sido=&gugun=&store=
'pageNo=' 다음에 페이지 번호를 붙여 다음 페이지 확인

(3) 파이썬 창에서 크롤링
BeautifulSoup 객체를 생성하여 파싱
from bs4 import BeautifulSoup
import urllib.request
result = []
for page in range(1,55): # 1 ~ 54페이지까지 반복해서 url 설정
Hollys_url = 'https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=%d&sido=&gugun=&store=' %page
print(Hollys_url)
html = urllib.request.urlopen(Hollys_url) # url 요청하여 응답받은 웹 페이지 저장
soupHollys = BeautifulSoup(html, 'html.parser') # BeautifulSoup 객체 생성
tag_tbody = soupHollys.find('tbody')
for store in tag_tbody.find_all('tr'):
if len(store) <= 3:
break
store_td = store.find_all('td')
store_name = store_td[1].string
store_sido = store_td[0].string
store_address = store_td[3].string
store_phone = store_td[5].string
result.append([store_name]+[store_sido]+[store_address]+[store_phone]) # tr 태그 하위의 td 태그 중에서 필요한 항목만 추출하여 result 리스트에 추가
크롤링된 내용 확인
# 결과가 저장된 result의 원소 개수 확인
len(result)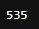
# 첫 번째 원소 확인
result[0]
# 마지막 원소 확인
result[534]
# 마지막 매장 정보가 저장되어 있는 store_td의 내용 확인
store_td
store_td[1].string
store_td[0].string
store_td[3].string
store_td[5].string
크롤링한 데이터 저장
import pandas as pd
hollys_tbl = pd.DataFrame(result, columns = ("store", "sido-gu", "address", "phone"))
hollys_tbl.to_csv("C:/Users/82109/OneDrive/바탕 화면/hollys.csv", encoding = "cp949", mode = "w", index = True)
(4) 파이썬 파일 작성하여 크롤링
from bs4 import BeautifulSoup
import urllib.request
import pandas as pd
import datetime
#[CODE 1]
def hollys_store(result):
for page in range(1,55):
Hollys_url = 'https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=%d&sido=&gugun=&store=' %page
print(Hollys_url)
html = urllib.request.urlopen(Hollys_url)
soupHollys = BeautifulSoup(html, 'html.parser')
tag_tbody = soupHollys.find('tbody')
for store in tag_tbody.find_all('tr'):
if len(store) <= 3:
break
store_td = store.find_all('td')
store_name = store_td[1].string
store_sido = store_td[0].string
store_address = store_td[3].string
store_phone = store_td[5].string
result.append([store_name]+[store_sido]+[store_address]+[store_phone])
return
#[CODE 0]
def main():
result = []
print('Hollys store crawling >>>>>>>>>>>>>>>>>>>>>>>>>>')
hollys_store(result) #[CODE 1] 호출
hollys_tbl = pd.DataFrame(result, columns = ('store', 'sido-gu', 'address','phone'))
hollys_tbl.to_csv("C:/Users/82109/OneDrive/바탕 화면/hollys.csv", encoding = 'utf-8', mode = 'w', index = True)
del result[:]
if __name__ == '__main__':
main()
'AI 기본 과정' 카테고리의 다른 글
| Python을 이용한 데이터 분석 - 통계분석 (1) (0) | 2022.06.05 |
|---|---|
| Python을 이용한 데이터 분석 - 라이브러리를 이용한 크롤링 (2) (0) | 2022.06.04 |
| Python을 이용한 데이터 분석 - API를 이용한 크롤링 (2) (0) | 2022.05.15 |
| Python을 이용한 데이터 분석 - API를 이용한 크롤링 (1) (0) | 2022.05.14 |
| Python을 이용한 데이터 분석 - Pandas (0) | 2022.05.10 |