ICT이노베이션스퀘어 AI기본과정(CNU) 교육을 듣고 정리한 내용입니다.
AI기본과정(CNU) 교육 자료를 참고하였습니다.
영문
[ 영문 분석 + 워드클라우드 ] 영문 문서 제목의 키워드 분석
1. 목표 설정
'Big data'와 관련된 키워드를 도출하여 분석
2. 핵심 개념 이해
(1) 텍스트 분석
1) 자연어 처리와 데이터마이닝이 결합하여 발전된 분야로 텍스트 데이터에서 정보를 추출하여 분석하는 방법
2) 단어에 대한 분석을 기본으로 함
3) 텍스트 분류, 텍스트 군집화, 감성 분석 등
(2) 전처리 : 분석 작업의 정확도를 높이기 위해 분석에 사용할 데이터를 먼저 정리하고 변환하는 작업
1) 정제 : 불필요한 기호나 문자를 제거하는 작업으로 주로 정규식을 이용하여 수행
2) 정규화 : 정제와 같은 의미지만 형태가 다른 단어를 하나의 형태로 통합하는 작업으로 대/소문자 통합, 유사 의미의 단어 통합 등이 있음
3) 토큰화 : 데이터를 토큰으로 정한 기본 단위로 분리하는 작업, 문장을 기준으로 분리하는 문장 토큰화, 단어를 기준으로 분리하는 단어 토큰화 등이 있음
4) 불용어 제거 : 의미가 있는 토큰을 선별하기 위해 조사, 관사, 접미사처럼 분석할 의미가 없는 토큰인 불용어 제거
5) 어간 추출 : 단어에서 시제, 단/복수, 진행형 등을 나타내는 다양한 어간을 잘라내어 단어의 형태를 일반화함
6) 표제어 추출 : 단어에서 시제, 단/복수, 진행형 등을 나타내는 다양한 표제어를 추출하여 단어의 형태를 일반화함, 품사를 지정하여 표제어를 추출하는 것이 가능
| 사용 단어 | 어간 추출 | 표제어 추출 |
| am | am | be |
| the going | the go | the going |
| having | hav | have |
(3) 워드클라우드
1) 텍스트 분석에서 많이 사용하는 시각화 기법
2) 문서의 핵심 단어를 시각적으로 돋보이게 만들어 키워드를 직관적으로 알 수 있게 하는 것
3) 출현 빈도가 높을수록 단어를 크게 나타냄
4) 방대한 양의 텍스트 정보를 다루는 빅데이터 분석에서 주요 단어를 시각화하기 위해 사용
3. 데이터 수집
http://www.riss.kr/index.do 접속 -> 검색창에 'Big data' 입력
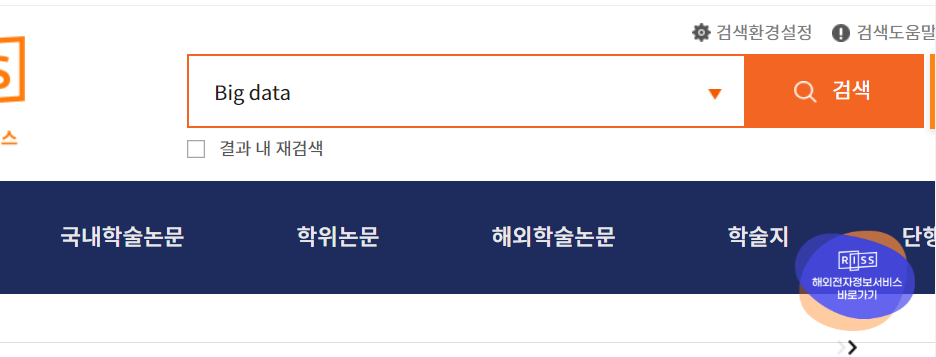
통합검색 결과 페이지에서 '해외학술논문' 메뉴 클릭

작성언어를 '영어'로 선택하고 실행
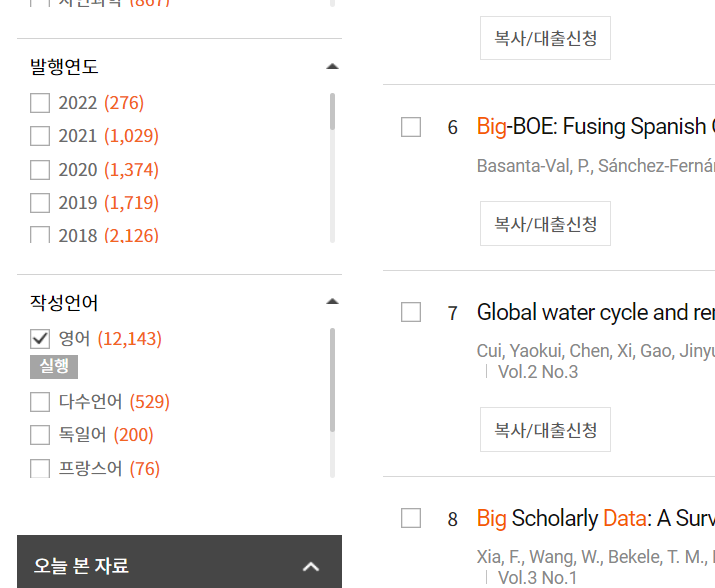
검색 결과 출력 개수 변경
현재 페이지 100개를 저장하기 위해 '내보내기' 메뉴 선택

다음과 같이 선택한 후 '내보내기' 클릭

다음 페이지로 이동하여 이전 과정 반복

다운로드한 폴더 확인

4. 데이터 준비
(1) 작업 준비
데이터 확인

My_Python 폴더 안에 text_data_1 폴더 생성

text_data_1 폴더에 myCabinetExcelData 파일 10개를 이동시키기

주피터랩을 실행하고 My_Python 폴더로 이동한 뒤 '+' 버튼을 클릭하고 Notebook의 'Python 3' 선택

파일 이름을 '영어 단어 분석'으로 변경
(2) 프로젝트에 필요한 파이썬 패키지 임포트
nltk의 리소스 다운로드
import nltk
nltk.download() # 최초 한 번만 설치, download 창이 뜨면 모두 선택하고 [Download] 버튼 클릭
패키지 임포트
import pandas as pd
import glob
import re
from functools import reduce
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from collections import Counter
import matplotlib.pyplot as plt
from wordcloud import STOPWORDS, WordCloud> glob : 경로와 이름을 지정하여 파일을 다루는 파일 처리 작업을 위한 모듈
> re : 메타 문자를 이용하여 특정 규칙을 작성하는 정규식을 사용하기 위한 모듈
> reduce : 2차원 리스트를 1차원 리스트로 차원을 줄이기 위한 모듈
> Counter : 데이터 집합에서 개수를 자동으로 계산하기 위한 모듈
(3) 데이터 조합 - 파일 병합
병합할 엑셀 파일 이름 10개를 리스트에 저장
all_files = glob.glob("text_data_1/myCabinetExcelData*.xls")
all_files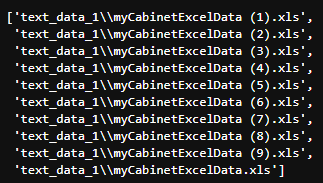
엑셀 파일을 읽어와서 파일 내용을 all_files_data에 추가
all_files_data = []
for file in all_files:
data_frame = pd.read_excel(file)
all_files_data.append(data_frame)
all_files_data[0]
all_files_data를 세로축을 기준으로 병합
all_files_data_concat = pd.concat(all_files_data, axis = 0, ignore_index = True)
all_files_data_concat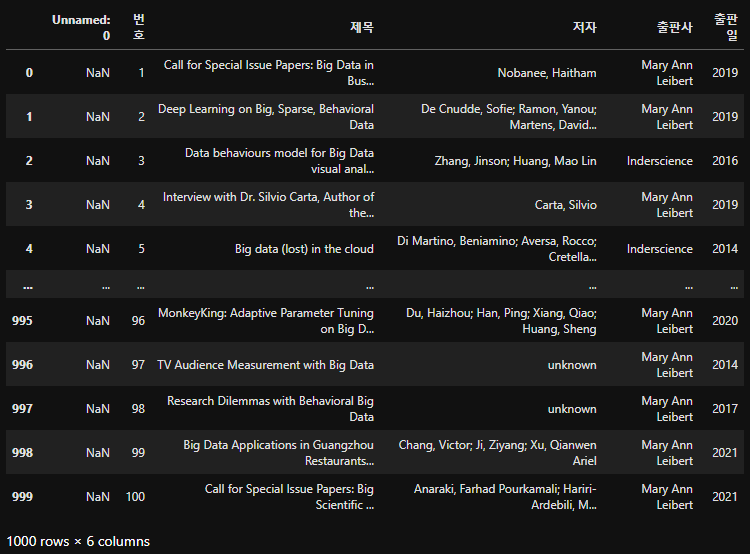
all_files_data_concat을 CSV 파일로 저장
all_files_data_concat.to_csv("text_data_1/riss_bigdata.csv", encoding = "utf-8", index = False)
(4) 데이터 전처리
"제목" 컬럼만 추출해 all_title에 저장
all_title = all_files_data_concat["제목"]
all_title
영어 불용어 불러와서 저장하기
stopWords = set(stopwords.words("english"))
표제어 추출 작업을 제공하는 WordNetLemmatizer 객체 생성
lemma = WordNetLemmatizer()
전처리
words = []
for title in all_title:
EnWords = re.sub(r"[^a-zA-Z]+", " ", str(title)) # 알파벳으로 시작하지 않는 단어를 공백으로 치환
EnWordsToken = word_tokenize(EnWords.lower()) # 소문자화, 토큰화
EnWordsTokenStop = [w for w in EnWordsToken if w not in stopWords] # 불용어 제거
EnWordsTokenStopLemma = [lemma.lemmatize(w) for w in EnWordsTokenStop] # 표제어 추출
words.append(EnWordsTokenStopLemma)
print(words)
# re.sub(정규 표현식, 대상 문자열, 치환 문자)
words를 1차원 리스트로 변환
words2 = list(reduce(lambda x, y: x+y, words))
print(words2)
# reduce(함수, 시퀀스)
5. 데이터 탐색 및 분석 모델 구축
(1) 데이터 탐색 - 단어 빈도 구하기
단어별 출현 빈도를 계산하여 딕셔너리 객체 생성
count = Counter(words2)
count
출현 빈도가 높은 상위 50개 단어
word_count = dict()
for tag, counts in count.most_common(50):
if(len(str(tag))>1):
word_count[tag] = counts
print("%s : %d" % (tag, counts))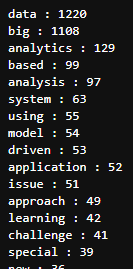
(2) 데이터 탐색 - 히스토그램
히스토그램
sorted_Keys = sorted(word_count, key = word_count.get, reverse = True) # x축 값
sorted_Values = sorted(word_count.values(), reverse = True) # y축 값
plt.bar(range(len(word_count)), sorted_Values, align = "center")
plt.xticks(range(len(word_count)), list(sorted_Keys), rotation = "85")
plt.show()
word_count 딕셔너리에서 'data'와 'big'을 제거한 히스토그램
del(word_count["data"])
del(word_count["big"])
sorted_Keys = sorted(word_count, key = word_count.get, reverse = True) # x축 값
sorted_Values = sorted(word_count.values(), reverse = True) # y축 값
plt.bar(range(len(word_count)), sorted_Values, align = "center")
plt.xticks(range(len(word_count)), list(sorted_Keys), rotation = "85")
plt.show()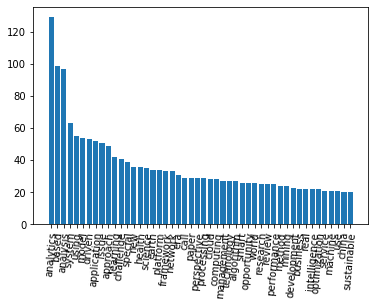
6. 결과 시각화
(1) 그래프 그리기
출판일을 기준으로 그룹을 생성하고 그룹별 데이터 개수를 doc_count 컬럼에 저장
all_files_data_concat["doc_count"] = 0 # doc_count 컬럼 추가
summary_year = all_files_data_concat.groupby("출판일", as_index = False)["doc_count"].count()
summary_year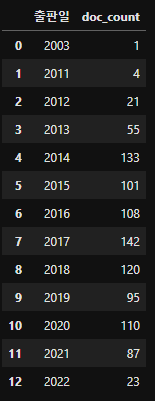
연도별 문서 개수 차트
plt.figure(figsize = (12, 5))
plt.xlabel("year")
plt.ylabel("doc-count")
plt.grid(True)
plt.plot(range(len(summary_year)), summary_year["doc_count"])
plt.xticks(range(len(summary_year)), [text for text in summary_year["출판일"]])
plt.show()
(2) 워드클라우드 그리기
워드클라우드
stopwords = set(STOPWORDS)
wc = WordCloud(background_color = "ivory", stopwords = stopwords, width = 800, height = 600)
cloud = wc.generate_from_frequencies(word_count)
plt.figure(figsize = (8,8))
plt.imshow(cloud)
plt.axis("off")
plt.show()
워드클라우드를 jpg 파일로 저장
cloud.to_file("text_data_1/riss_bigdata_wordCloud.jpg")'AI 기본 과정' 카테고리의 다른 글
| Python을 이용한 데이터 분석 - 텍스트 빈도 분석 (2) (0) | 2022.06.22 |
|---|---|
| Python을 이용한 데이터 분석 - 통계분석 (2) (0) | 2022.06.06 |
| Python을 이용한 데이터 분석 - 통계분석 (1) (0) | 2022.06.05 |
| Python을 이용한 데이터 분석 - 라이브러리를 이용한 크롤링 (2) (0) | 2022.06.04 |
| Python을 이용한 데이터 분석 - 라이브러리를 이용한 크롤링 (1) (0) | 2022.05.30 |